
今天開始,接下來的幾篇文章會開始分享一些工作中遇到的真實案例。
但是今天要帶大家探討的這個案例,是我們公司之前一位前輩 David Cheng 在 2024 K8s Summit 演講中提到的其中一個問題:「DNS 封包根本沒進去 NodeLocal DNS Cache 」。
如果你對 Kubernetes 網路議題有興趣,非常推薦打開那場演講的簡報,裡面還有其他踩坑經驗!我自己當初就是從中學到很多實戰經驗。
這案例並不是我自己遇到的,當時我還沒入職目前這間公司,而我覺得這案例很經典、很值得拿出來探討!畢竟 NodeLocalDNS Cache 是 K8s Cluster 都會使用到的一個元件,所以今天這篇文章就要實際重現當時的問題現象,並一步步帶大家一起解決它。
為了復現問題,我們需要先在 K8s Cluster 安裝 NodeLocalDNS Cache,關於 NodeLocalDNS Cache 是什麼由於我預設讀者已經有 K8s 基礎能力,若對於不認識 NodeLocalDNS Cache 的讀者可以參考官方文件
這裡會很單純地說明安裝步驟,安裝過程中有一些詳細的內容如果有興趣再請讀者自行參考官方文件
補充說明:由於我們啟用 kubeProxyReplacement 功能,請依照 Cilium 官方文件提供的
node-local-dns.yaml安裝,不要使用 K8s 官方文件提供的nodelocaldns.yaml安裝,否則後續 DNS 查詢會遇到;; communications error to 10.96.0.10#53: connection refused錯誤
$ wget https://raw.githubusercontent.com/cilium/cilium/1.18.1/examples/kubernetes-local-redirect/node-local-dns.yaml
$ kubedns=$(kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}) && sed -i "s/__PILLAR__DNS__SERVER__/$kubedns/g;" node-local-dns.yaml
$ kubectl apply -f node-local-dns.yaml
可以查看 DaemonSets,確認 node-local-dns 的狀態:
$ kubectl get ds -n kube-system node-local-dns
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
node-local-dns 3 3 3 3 3 <none> 49s
安裝好 NodeLocalDNS Cache 後,可以來先起一個 netshoot Pod,待會會需要使用:
kubectl run netshoot --image=nicolaka/netshoot -n default -- sleep infinity
先查看 netshoot Pod 裡面的 /etc/resolv.conf 內容,主要是想看裡面的 nameserver 是指向哪個 IP 地址:
$ kubectl exec netshoot -- cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local ap-northeast-1.compute.internal
nameserver 10.96.0.10 # <-- 指向的是 kube-dns svc ClusterIP
options ndots:5
從上方輸出可注意到 nameserver 10.96.0.10 , 10.96.0.10 其實就是 kube-dns Service ClusterIP
我們先簡單驗證一下 netshoot 現在 DNS 解析是正常的:
$ kubectl exec netshoot -- dig google.com
; <<>> DiG 9.20.10 <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49886
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
; COOKIE: a2d9476471fa322d (echoed)
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 30 IN A 142.250.196.110
;; Query time: 5 msec
;; SERVER: 10.96.0.10#53(10.96.0.10) (UDP)
;; WHEN: Fri Oct 10 22:37:58 UTC 2025
;; MSG SIZE rcvd: 77
從上方來看,DNS 解析是正常的,通常這種情況下大家都會認為沒事!
直到 Cluster 規模持續變大,或是 Workload 越來越重,就會像 2024 K8s Summit 演講內提到的「我們公司遇到 DNS 間歇性 Timeout」
一查才會發現事情大條,原來 DNS 查詢封包根本就沒進 NodeLocalDNS Cache…
我們現在就來驗證 NodeLocalDNS Cache 真的沒收到封包!
netshoot 住在 worker-1 上,所以我們連進去 worker-1 的 Cilium Agent,接著來使用 hubble observe 來觀察封包:
補充說明:我是使用
hubble observe,但是讀者們也可以參考 2024 K8s Summit 演講中 David 所使用 pwru 來驗證封包真的沒丟給 NodeLocalDNS Cache
# worker-1 上的 cilium-agent 裡面
hubble observe --protocol udp --port 53 -f
執行 hubble observe 後,使用 netshoot Pod 發出 DNS 查詢封包
kubectl exec netshoot -- dig google.com
然後查看 hubble observe 實際抓到的 flow ,如下:

你會注意到,抓到的 flwo 怎麼完全沒有 node-local-dns 的蹤影?
正如 2024 K8s Summit 演講內提到的,關鍵就是要配置 Local Redirect Policy (後簡稱 LRP)
想要配置 Local Redirect Policy 必須確保我們的 K8s Cluster 裡面有安裝 CRD CiliumLocalRedirectPolicy
具體安裝 CRD 步驟如下:
以 helm 為例,執行以下指令將 Local Redirect Policy 啟用 :
helm upgrade cilium cilium/cilium --version 1.18.1 \
--namespace kube-system \
--reuse-values \
--set localRedirectPolicies.enabled=true
重啟 cilium-operator 和 cilium-agent
kubectl rollout restart deploy cilium-operator -n kube-system
kubectl rollout restart ds cilium -n kube-system
確認集群內已經安裝好 CiliumLocalRedirectPolicy CRD:
$ kubectl get crd -A | grep cilium
...
ciliumlocalredirectpolicies.cilium.io 2025-10-10T23:17:00Z
...
然後配置 LRP:
# lrp-nodelocaldns.yaml
apiVersion: cilium.io/v2
kind: CiliumLocalRedirectPolicy
metadata:
name: nodelocaldns
namespace: kube-system
spec:
redirectFrontend:
serviceMatcher:
serviceName: kube-dns
namespace: kube-system
redirectBackend:
localEndpointSelector:
matchLabels:
k8s-app: node-local-dns
toPorts:
- port: "53"
protocol: UDP
name: "dns"
- port: "53"
protocol: TCP
name: "dns-tcp"
部署:
kubectl apply -f lrp-nodelocaldns.yaml
現來來驗證看看是不是可以成功把封包送進去 NodeLocalDNS Cache 了,我們連進去 worker-1 的 Cilium Agent,一樣來使用 hubble observe 來觀察封包:
# worker-1 上的 cilium-agent 裡面
hubble observe --protocol udp --port 53 -f
執行 hubble observe 後,使用 netshoot Pod 發出 DNS 查詢封包
kubectl exec netshoot -- dig google.com
然後查看 hubble observe 實際抓到的 flow ,如下:
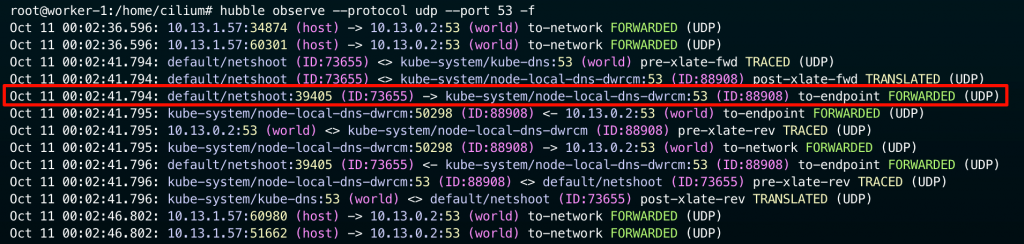
從上面的輸出,就可以確定封包確實有進入 node-local-dns pod
到這裡,我們成功解決了當初的問題:「DNS 查詢封包根本就沒進 NodeLocalDNS Cache」
讀者們照著做問題如期解決了,但是可能會很想知道背後的原理:「為什麼拍這個 LRP 就解決我們的問題了?」
先來簡單說明 LRP 是什麼:
👉 是 Cilium 提供的一個重導向功能,會利用 Cilium 的 eBPF Datapath 來攔截發往特定 frontend(IP 或 Service)的 Pod 流量,並將其重新導向到運行在同一節點上的 Backend Pod 。
LRP 透過名為 CiliumLocalRedirectPolicy 的 CRD 進行設定,以下是 YAML 範例搭配註解解釋:
apiVersion: cilium.io/v2
kind: CiliumLocalRedirectPolicy
metadata:
name: nodelocaldns
namespace: kube-system
spec:
# redirectFrontend 定義了需要被攔截的流量,即 Policy 的觸發條件
redirectFrontend:
# ServiceMatcher 用於匹配發往 k8s Service 的流量
serviceMatcher:
# 目標 Service 的名稱
serviceName: kube-dns
# 目標 Service 的 namespace
namespace: kube-system
# (Optional) toPorts 可用於僅重新導向 Service 的特定 port
# 如果未指定,則該 Service 的所有 port 流量都將被重新導向
# redirectBackend 定義了流量被攔截後應重新導向到哪
redirectBackend:
# localEndpointSelector 用來指定同一節點上的目標後端 Pod
localEndpointSelector:
matchLabels:
k8s-app: node-local-dns
# toPorts 指定後端 Pod 接收流量的 port
toPorts:
- port: "53"
protocol: UDP
name: "dns"
- port: "53"
protocol: TCP
name: "dns-tcp"
理解 LRP 基本觀念後,當我們配置 LRP 下去後白話來說就是:
👉 當節點上的任何 Pod 查詢 kube-dns service 時,eBPF datapath 會攔截該封包,並將其直接重新導向到同一節點上的 node-local-dns。
那如果深入更底層一點,其實 LRP 配置下去之後,他會把 Service Type 從 Cluster IP 改成 LocalRedirect ,我們實際連進去 worker-1 的 cilium-agent 查看一下 Service BPF Map:
# 在 worker-1 的 cilium-agent 裡面
# 10.244.2.69 是 node-local-dns-dwrcm 的 IP
$ cilium-dbg service list
...
4 10.96.0.10:53/TCP LocalRedirect 1 => 10.244.2.69:53/TCP (active)
5 10.96.0.10:53/UDP LocalRedirect 1 => 10.244.2.69:53/UDP (active)
6 10.96.0.10:9153/TCP ClusterIP 1 => 10.244.1.33:9153/TCP (active)
2 => 10.244.1.235:9153/TCP (active)
從上面的輸出,你就可以發現 10.96.0.10 (kube-dns service) 映射到的 Backend Pod 就是 10.244.2.69 (節點上的 node-local-dns Pod)
那如果有懂 Cilium Pod-to-Service Datapath 你到這裡就可以意會到背後的封包怎麼走的,我在這裡就不贅述了
如果對於 Pod-to-Service Datapath 不熟悉或是忘記了,可以複習 [Day 20] 為什麼你在抓封包時找不到 Service ClusterIP?Cilium Pod to Service Datapath 解析
今天這篇文章我們實際重現了有安裝 Cilium 的 K8s Cluster 在導入 NodeLocalDNS Cache 後會遇到的經典問題:「DNS 查詢封包並沒有真的進入 NodeLocalDNS Cache」。
透過 hubble observe 的封包追蹤,我們親眼看到查詢封包依然是直接發往 kube-dns 的 ClusterIP,完全沒有被導向到節點上的 node-local-dns Pod。
最後,我們透過配置 Cilium Local Redirect Policy (LRP) 成功讓封包在 eBPF 層被攔截,並重新導向至同一節點的 node-local-dns Pod,使得 DNS 查詢真正命中本地 cache,大幅降低跨節點的 DNS 延遲與負載。

 iThome鐵人賽
iThome鐵人賽